아래 블로그를 참고해서 모델에 관한 주석과 Data Flow를 그려봤습니다.
모델을 이해하는데 도움이 되었으면 좋겠습니다.
FM 논문 링크입니다. https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
홍러닝 블로그님의 게시글을 참고하여 제작하였습니다. https://hongl.tistory.com/242
RecSys - Factorization Machines (1)
유튜브, 넷플리스, 이커머스 등의 플랫폼을 사용하다보면 연관된 영상과 제품이 여러 사용자의 다양한 데이터와 머신러닝 알고리즘에 기반하여 추천됩니다. 내가 이 플랫폼을 처음 사용한다거
hongl.tistory.com

FM에 전체 구조는 위에 그림처럼 구성됩니다.
차례대로 살펴 보겠습니다.
Feature_Linear의 Data Flow입니다.

feature은 특징 컬럼입니다. len(feature)하면 특징의 총 개수가 됩니다.
X는 아이템의 특징이 표현된 데이터입니다. 여기서 offsets은 생략했는데, 저는 성능을 좋게 하기 위한 수단으로 보고 모델 이해에 꼭 필요하지 않다 생각하여 생략했습니다. 실제 코드에서는 구현되어 있습니다.
임베딩의 표현은 단어사전으로 생각하시면 됩니다. sum(feature) 만큼이 단어량을 가진 사전으로 Input으로 들어오는 데이터를 표현한다 이해하시면 됩니다.
torch.sum()은 dim에 따라 차원을 합쳐 주는 함수입니다. 여기서는 dim=1을 주어 첫번째 차원에 맞추어 합쳤습니다.
Feature_Embedding의 Data Flow입니다.

Factorziation_Machine의 Data Flow입니다.
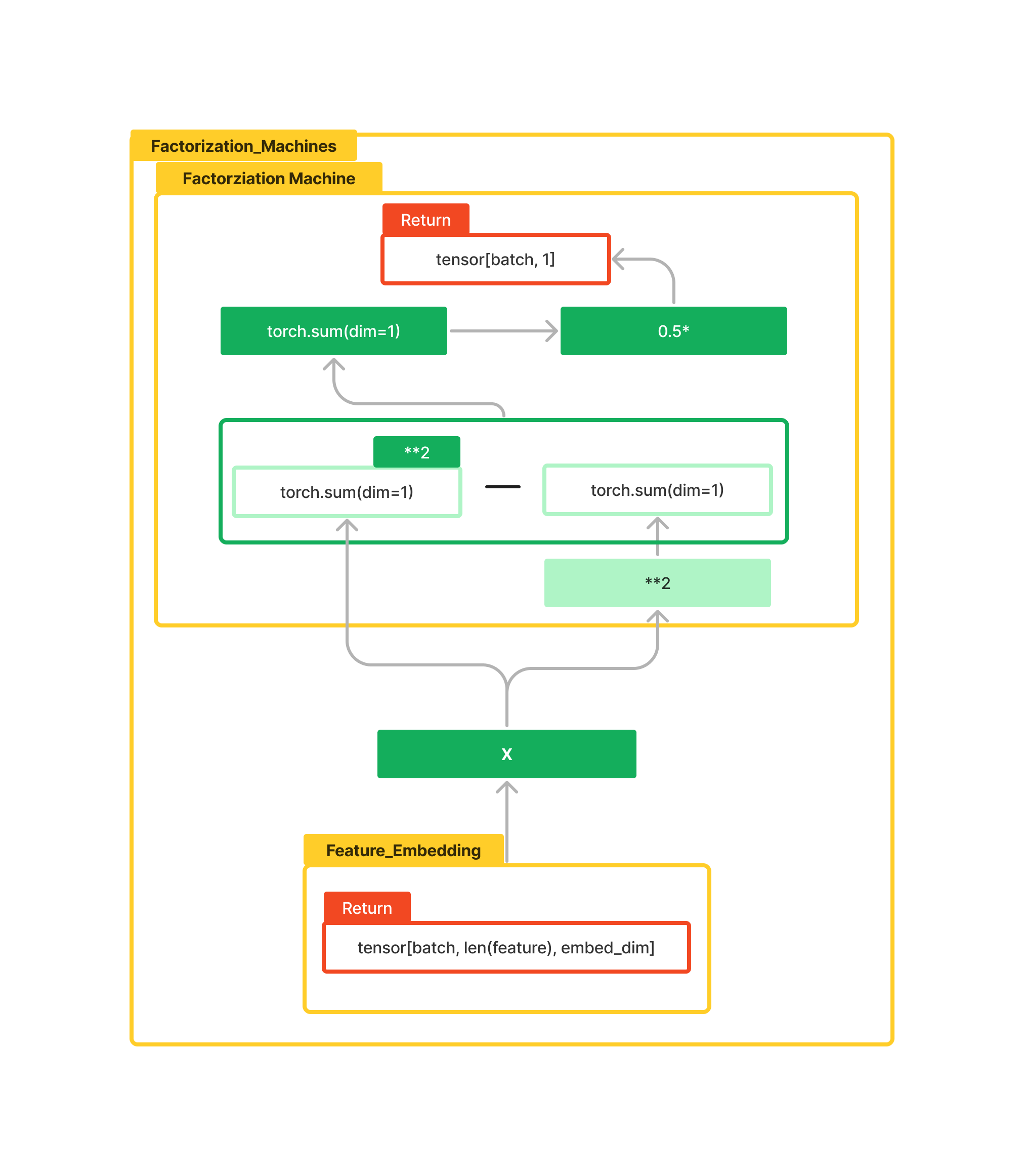
여기서 X는 위에 정의한 Feature_Embedding이 들어옵니다.
곱셈의 표현은 " * ", 제곱의 표현은 " ** "으로 표현했습니다.
여기서 초록색 블록은 전체를 제곱하는 것이고, 연두색은 X의 값을 제곱하는 것을 의미합니다.
따라서 전체 Data Flow는 아래와 같습니다.

가운데 노란색 플러스 표시는 덧셈을 의미합니다.
연산이 끝나고 Sigmoid를 활용해서 확률 값을 표현했습니다.
모델 이해에 조금이나마 도움이 되었으면 좋겠습니다.
감사합니다.
'데이터분석 > Model_Analysis' 카테고리의 다른 글
| [논문 리뷰] 추천 시스템 DeepFM(Factorization Machines) 분석 (0) | 2023.08.02 |
|---|

댓글